Inside Resemble AI: Generate, Verify, Detect
Resemble AI occupies a unique position in the AI audio market: it is the only platform that simultaneously generates synthetic voices, embeds invisible provenance watermarks at the moment of creation, and detects deepfakes across audio, image, and video — all under one unified infrastructure.
While competitors either build voice generators or detection tools, Resemble built both from the same foundational research, giving it a structural detection advantage no pure-play competitor can replicate.
Its open-source Chatterbox TTS model is MIT-licensed, runs on-premise without API keys or rate limits, and was preferred by 63.75% of blind evaluators over ElevenLabs — making it simultaneously the most enterprise-grade and most developer-accessible platform in this review series.
Key Capabilities
The Chatterbox family includes three variants: the original high-quality model with emotion exaggeration control and zero-shot voice cloning from 5 seconds of audio; Chatterbox Multilingual for 23+ languages; and Chatterbox Turbo, the fastest open-source TTS model available in 2026 with paralinguistic tagging for non-speech sounds like laughter and breathing.
Every generation from Chatterbox is automatically watermarked using PerTh — a Perceptual Threshold deep neural watermarker that embeds imperceptible, indestructible provenance data into every audio file using psychoacoustic masking principles.
On the detection side, Resemble Detect achieves 96.7% multimodal deepfake detection accuracy across WAV, FLAC, MP3, WEBM, M4A, and OGG formats — outperforming every competing architecture in independent benchmarks — and has been battle-tested against 160+ generative AI models.
The managed cloud platform at app.resemble.ai adds voice agents, AI voice changer, speech-to-text, audio enhancement, audio editing, identity search, and a Chrome extension for real-time deepfake detection while browsing.
Who Gets the Most Out of It
Developers building voice AI products choose Chatterbox over ElevenLabs for the MIT license freedom, on-premise deployment capability, and per-second pricing ($0.0005/sec for TTS) that scales more predictably than character-based billing at volume.
Security teams at enterprises and broadcasters use Resemble Detect to scan media libraries and live audio streams for deepfake content — the platform reports 1,567 verified deepfake incidents and $1.28B in documented fraud in its 2025 Deepfake Threat Report.
Game studios, film producers, and interactive media teams use the emotion exaggeration parameter — a unique single-dial control from monotone to dramatically expressive — alongside zero-shot voice cloning for character voice production at speed and scale.
Enterprise compliance teams in healthcare, finance, and legal require the on-premise deployment, SOC 2 Type II SLA, and SSO/SAML authentication — all available on the Enterprise plan.
Is It Worth It?
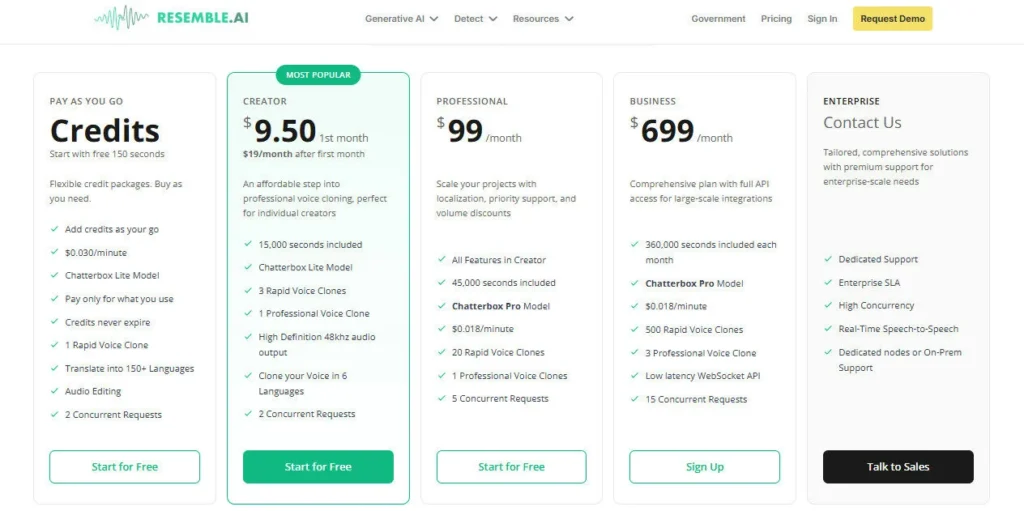
The Flex plan's pay-as-you-go pricing with credits that never expire and $0 to start makes Resemble AI the most financially flexible entry point in this review series — you pay only for what you process, with no monthly subscription fee unless you choose add-ons.
At $0.0005/second for TTS, a one-hour audio project costs approximately $1.80 — significantly cheaper than ElevenLabs' character-based rates at comparable quality.
The open-source Chatterbox model is entirely free forever under MIT license — no credits, no API keys, no rate limits — making it the right choice for developers who want to self-host.
The honest caveats: the platform has a steeper setup curve than consumer-first tools like DupDub or Acoust, and the enterprise features (SOC 2 SLA, SSO, custom model training) are gated behind a custom Enterprise contract rather than a published fixed price.