MiniMax Audio in Action
MiniMax Audio is the consumer-facing voice platform from MiniMax, the Chinese AI research company whose Speech 2.8 HD model currently holds the #1 position on both the Artificial Analysis Speech Arena and the Hugging Face TTS Arena — outperforming OpenAI TTS and ElevenLabs in blind user evaluations for naturalness and prosody stability.
It's not a marketing claim from a startup: these are verified third-party leaderboard rankings based on thousands of pairwise human comparisons.
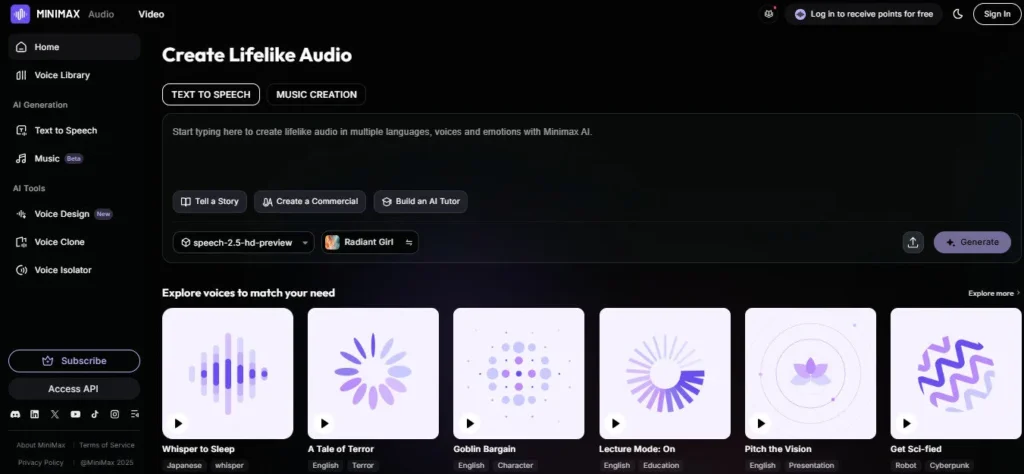
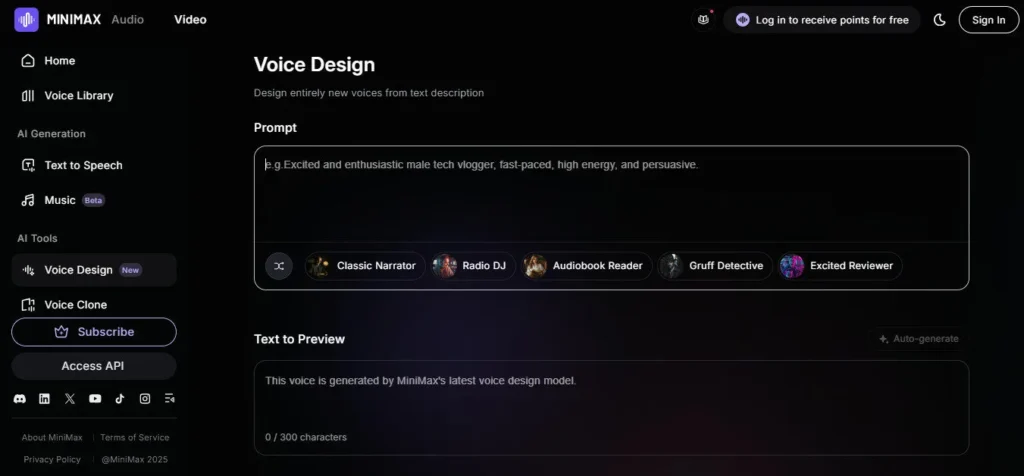
You get that same model in a free browser app at minimax.io/audio, with 10,000 credits per month, a voice cloning engine that needs just 10 seconds of audio, a Voice Design tool that builds custom voices from text prompts, and an AI music generator — all available without a credit card.
Key Capabilities
The Speech 2.8 HD model uses an autoregressive Transformer backbone with a hybrid Flow-VAE decoder — an architecture that reconstructs audio waveforms rather than just predicting tokens, which is why the output sounds more physically real than traditional neural TTS.
Emotion control uses inline sound tags inserted directly into your script: [laugh], [sigh], [clear throat], [happy], [fearful], and more — the same approach ElevenLabs uses with audio tags, but in MiniMax's implementation.
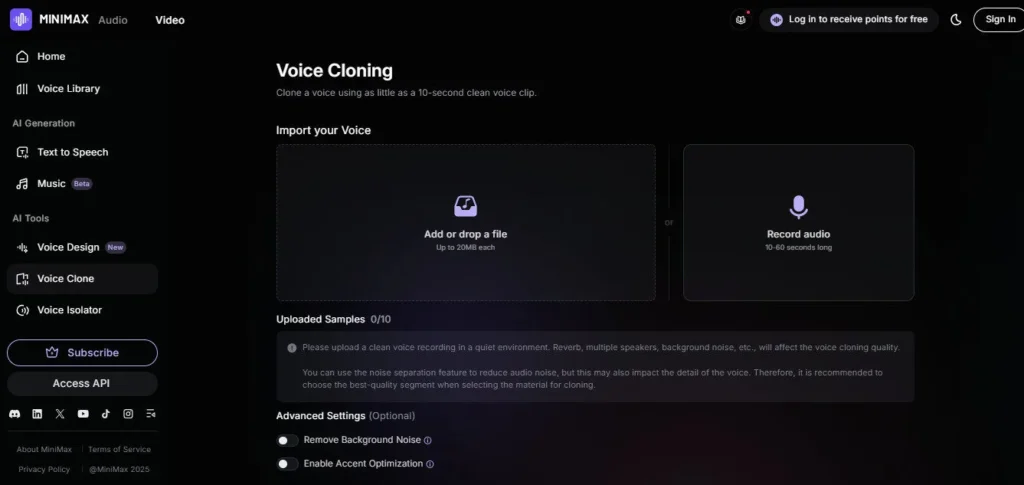
The voice cloning engine captures pitch, cadence, and accent from a 10-second clean recording and produces a clone with up to 99% similarity to the original in independent testing, with cross-language output in 40+ languages on the same clone.
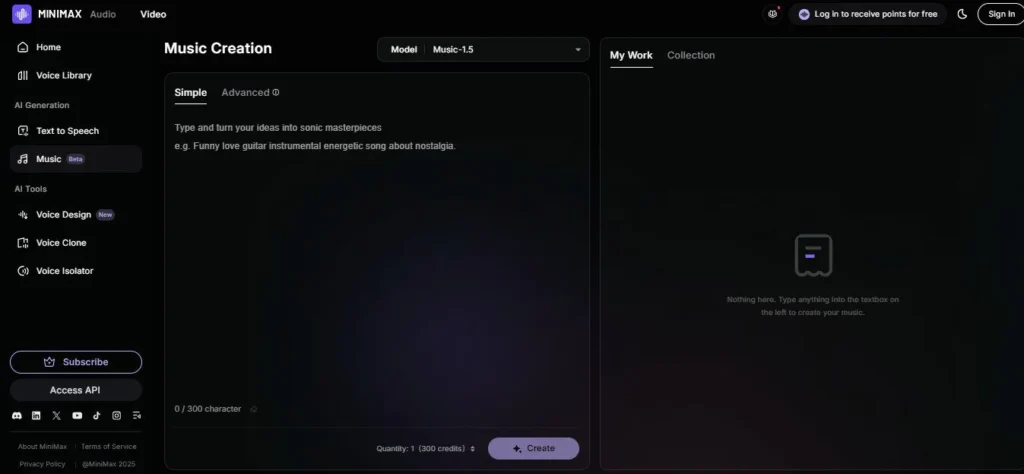
The Music-2.6 and Music-Cover models handle text-to-music generation and cover creation from reference audio with one-step style transfer and auto lyrics extraction.
Who Gets the Most Out of It
Developers building real-time voice AI applications use the Speech 2.8 Turbo API variant — confirmed at under 250ms latency — for IVR, voice agents, chatbots, and interactive game NPC dialogue at $60 per million characters for Turbo and $100 per million for HD, which is 40–85% cheaper than ElevenLabs at comparable volume.
Content creators on YouTube, TikTok, and podcasting platforms use the free app for multilingual voiceovers, cloning their own voice once and applying it across 40+ languages without a subscription.
Music producers use Music-Cover to generate cover versions of songs from reference audio, applying style transfer and modifying lyrics in two-step workflows without a DAW or live vocalist.
Researchers and enterprise teams access MiniMax Audio's models through the Cloudflare AI Gateway, AWS Marketplace, and Replicate — making it one of the most accessible frontier TTS models across cloud infrastructure.
Is It Worth It?
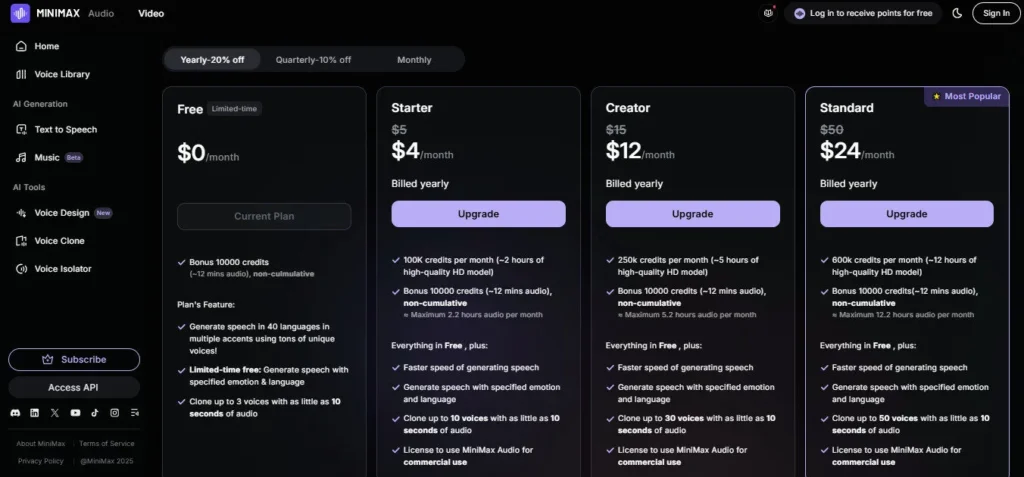
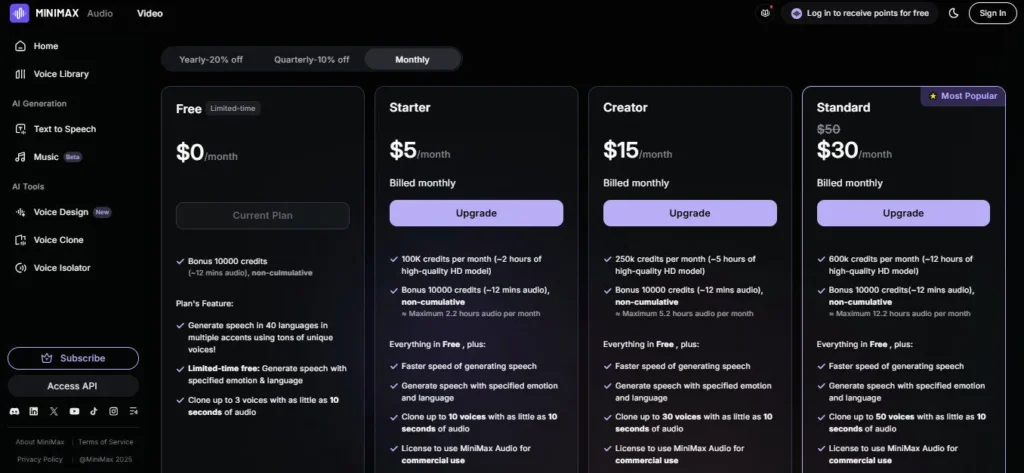
The free plan's 10,000 monthly credits with no credit card is a genuine evaluation tool — not a crippled demo. Paid character packs start at $5/month for 100,000 characters, and the API pay-as-you-go Turbo rate of $60 per million characters makes MiniMax Audio the most cost-competitive frontier TTS model available in 2026 for developer use cases.
Telnyx benchmarks confirmed MiniMax Speech 2.6 matched or exceeded ElevenLabs V3 Alpha in long-form stability and structured information delivery at a fraction of the cost.
The honest caveats: the consumer web app interface is less polished than ElevenLabs or DupDub, the voice library of 17+ preset characters is smaller than competing platforms, and some reviewers note the output can still sound slightly robotic in casual, conversational registers compared to ElevenLabs' most expressive models.